Caso de estudio
Agentes cloud de Jenkins en Kubernetes sobre AWS EKS
Caso de estudio detallado sobre la migración de Jenkins desde una sola instancia EC2 hacia agentes elásticos en Kubernetes sobre EKS con Karpenter, Jenkinsfiles y Kaniko.
Resumen de resultados
Fallas de build relacionadas con infraestructura
Tasa de builds no exitosos
Builds exitosos
Espera en cola de pipeline (p95)
Agentes cloud de Jenkins en Kubernetes
Resumen ejecutivo
BlueOrbit operaba Jenkins originalmente en una sola instancia EC2, donde el controlador también ejecutaba builds como agente. Ese modelo funcionó al inicio, pero se convirtió en un cuello de botella conforme crecieron el alcance de entrega y la carga del equipo.
La plataforma se rediseñó para ejecutar agentes cloud de Jenkins sobre Kubernetes, usando Karpenter para capacidad elástica. Las cargas de CI quedaron aisladas en node pools dedicados, con Spot como capacidad preferida y On-Demand como respaldo.
Desde una perspectiva de arquitectura, esta migración movió al equipo de builds estáticos basados en host a una infraestructura de build escalable, guiada por políticas, con mejor aislamiento de cargas y operación más predecible.
Capítulo 1 - Panorama general
1.1 Entendiendo el estado actual
Antes de la migración, Jenkins corría en un solo host EC2. Ese mismo host ejecutaba tanto el Jenkins controller como el proceso de agente integrado.
Al sumar nuevos proyectos, este diseño se volvió más difícil de operar. El equipo tuvo que mantener múltiples toolchains directamente en el host (por ejemplo PHP, Node y Docker CLI), y la gestión de dependencias/versiones se volvió cada vez más frágil entre pipelines.
El equipo también tenía jobs legacy tipo freestyle y encadenados que fueron útiles al inicio, pero más difíciles de mantener con el tiempo frente a flujos pipeline-as-code.
1.2 Vista arquitectónica del estado actual (antes)

Fuente del diagrama: diagrams/jenkins-current-state-before.mmd
1.3 Retos clave
- Un solo host EC2 limitaba el escalamiento cuando aumentaba la concurrencia de pipelines.
- El mantenimiento de herramientas a nivel host se volvió pesado con mayor diversidad tecnológica entre proyectos.
- Los jobs freestyle/encadenados hicieron más difícil el seguimiento de cambios y la gestión de ciclo de vida.
- La visibilidad por etapas y el troubleshooting eran más débiles que con flujos pipeline-as-code.
1.4 Plan propuesto
El enfoque de migración tuvo tres frentes principales: introducir capacidad de CI dedicada en Kubernetes, conectar Jenkins a esa capacidad mediante agentes cloud de Kubernetes, y mover progresivamente los jobs hacia pipelines basados en Jenkinsfile. El diseño también reemplazó builds de imágenes en host por herramientas de build nativas de contenedores que encajan con la ejecución en pods.
Evaluamos plataformas de CI alternativas, pero priorizamos una migración basada en Jenkins para preservar pipelines existentes y reducir riesgo de transición.
Capítulo 2 - Implementación
2.1 Configuración del ecosistema EKS
La plataforma ya corría sobre EKS, por lo que la migración se enfocó en integrar Jenkins de forma limpia al modelo de cluster existente. Se usó un namespace aislado para agentes de build de Jenkins y permisos IAM acotados a acciones relevantes de CI.
2.2 Configuración de Karpenter para cargas de build de Jenkins
Este caso de estudio se centra en la configuración de Karpenter que soporta agentes cloud de Jenkins.
2.2.1 Estrategia de capacidad
La capacidad de CI se divide en un pool Spot-first y un pool On-Demand de respaldo. Los pesos de NodePool priorizan Spot, mientras que los límites de CPU y restricciones de instancias mantienen la capacidad dentro de límites predecibles. Configuraciones de consolidación y expiración ayudan a reducir costo ocioso.
2.2.2 Modelo de aislamiento de cargas
Las cargas de CI se aíslan usando límites por labels y taints (workload=ci). Las pod templates de Jenkins aplican nodeSelector y tolerations compatibles, manteniendo separadas las cargas de build respecto a cargas runtime/de aplicación.
2.2.3 Baseline de node class
Los pools de CI usan un baseline compartido de EC2 node class con Amazon Linux 2023, selectores de red para descubrimiento de cluster, un role de nodo dedicado para Karpenter y volúmenes raíz cifrados dimensionados para actividad de build.
2.2.4 Validación a nivel arquitectura
Este caso de estudio valida resultados de comportamiento más que pasos de despliegue.
La validación se enfocó en cuatro comprobaciones: los pods de Jenkins se programan solo sobre capacidad etiquetada para CI, Spot se usa por defecto, los builds continúan cuando se requieren nodos On-Demand de respaldo, y las cargas de CI se mantienen aisladas de cargas no-CI.
Capítulo 3 - Arquitectura de solución
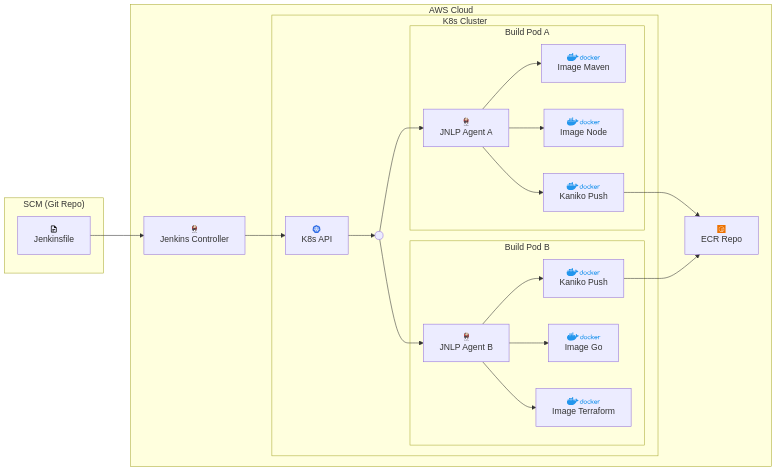
3.1 Vista arquitectónica de la solución (después)

Fuente del diagrama: diagrams/jenkins-k8s-pipeline.mmd
3.2 Modelo de ejecución
El Jenkinsfile define qué pod template e imágenes de contenedor se usan en cada etapa. Cada pod de build incluye un contenedor agente JNLP más uno o más contenedores específicos por tarea. Esto permite que distintos jobs usen imágenes de herramientas diferentes sin cambiar el host del Jenkins controller.
Capítulo 4 - Resultados
4.1 Enfoque de medición
Para mantener una comparación justa, se usa el mismo conjunto de métricas de CI a nivel plataforma en ambos periodos.
| Métrica | Por qué se monitorea |
|---|---|
| Proxy de aprovisionamiento de agente (p50) | Mide qué tan rápido queda disponible la capacidad de build después del scheduling. |
| Espera en cola de pipeline (p95) | Refleja presión de cola en cola larga y tiempo de espera bajo carga. |
| Fallas de build relacionadas con infraestructura (%) | Separa fallas de plataforma de fallas de aplicación/pruebas. |
| Tasa de builds no exitosos (%) | Proporciona una señal general de confiabilidad en pipelines seleccionados. |
| Builds exitosos (conteo) | Muestra throughput práctico dentro del alcance medido. |
4.2 Vista de resultados
- Periodo antes:
2025-12-15 -> 2026-01-12 - Periodo después:
2026-01-19 -> 2026-02-16 - Cobertura de métricas de cola/aprovisionamiento: 100% en ambos periodos
| KPI | Antes | Después | Delta |
|---|---|---|---|
| Proxy de aprovisionamiento de agente (p50, seg) | 6.92 | 6.79 | -1.88% |
| Espera en cola de pipeline (p95, seg) | 9.90 | 9.73 | -1.71% |
| Fallas de build relacionadas con infraestructura (%) | 39.13 | 22.00 | -43.78% |
| Tasa de builds no exitosos (%) | 43.48 | 26.00 | -40.20% |
| Builds exitosos (conteo) | 13 | 37 | +184.62% |
El pico de concurrencia observado en esta muestra se mantuvo en 2 -> 2. Esto depende de la demanda y no representa el techo de concurrencia configurado en la plataforma.
Las métricas de duración de build se excluyen intencionalmente de esta comparación porque la mezcla de cargas cambió después de añadir nuevas etapas/jobs, lo que hace no equivalente una comparación directa de duración antes/después.
4.3 Impacto notable
En la práctica, la migración movió la ejecución de builds desde límites estáticos de host hacia capacidad elástica y volvió más consistentes los entornos de build mediante tooling basado en imágenes. El equipo también pudo añadir más checks pre-merge (por ejemplo linting y análisis estático) y ejecutar validación de ramas en paralelo sin regresión visible en presión de cola durante los periodos medidos.
Capítulo 5 - Lecciones aprendidas
5.1 Qué funcionó
Node pools dedicados para CI, scheduling Spot-first con respaldo On-Demand y agentes Jenkins basados en pods ofrecieron un buen equilibrio entre control de costos, confiabilidad y claridad operativa.
5.2 Qué resultó más difícil de lo esperado
Normalizar jobs legacy freestyle hacia pipeline-as-code requirió más esfuerzo de lo esperado, y la observabilidad temprana entre cola/aprovisionamiento/comportamiento de nodos estuvo fragmentada.
5.3 Qué cambiaríamos en v2
- Definir instrumentación de KPIs y dashboards antes de iniciar la migración.
- Agregar policy checks que obliguen
nodeSelector/tolerationsde CI en pod templates de Jenkins.