Case Study
Jenkins Kubernetes Cloud Agents on AWS EKS
A detailed case study on migrating Jenkins from a single EC2 host to elastic Kubernetes agents on EKS with Karpenter, Jenkinsfiles, and Kaniko.
Results Snapshot
Infrastructure-related build failures
Build non-success rate
Successful builds
Pipeline queue wait (p95)
Jenkins Kubernetes Cloud Agents
Executive Summary
BlueOrbit originally ran Jenkins on a single EC2 instance, where the controller also handled builds as the agent. That model worked early on, but it became a bottleneck as delivery scope and team load increased.
The platform was redesigned to run Jenkins cloud agents on Kubernetes, with Karpenter providing elastic capacity. CI workloads are isolated on dedicated node pools, with Spot preferred by default and On-Demand used as fallback.
From an architectural perspective, this migration moved the team from static host-based builds to policy-driven, scalable build infrastructure with better workload isolation and more predictable operations.
Chapter 1 - Overview
1.1 Understanding the current state
Before the migration, Jenkins was running on a single EC2 host. The same host ran both the Jenkins controller and the built-in Jenkins agent process.
As new projects were added, this design became harder to operate. The team had to maintain multiple toolchains directly on the host (for example PHP, Node, and Docker CLI), and dependency/version management became increasingly fragile across pipelines.
The team also had legacy freestyle and chained jobs that were useful at first but harder to maintain over time compared with pipeline-as-code workflows.
1.2 Current state architectural view (before)

Diagram source: diagrams/jenkins-current-state-before.mmd
1.3 Key challenges
- A single EC2 host limited scaling as pipeline concurrency demand increased.
- Host-level tool maintenance became heavy as project stack diversity grew.
- Freestyle/chained jobs made change tracking and lifecycle management harder.
- Visibility into pipeline stages and troubleshooting was weaker than pipeline-as-code flows.
1.4 Proposed plan
The migration approach had three main tracks: introduce dedicated CI capacity on Kubernetes, connect Jenkins to that capacity through Kubernetes cloud agents, and progressively move jobs toward Jenkinsfile-based pipelines. The design also replaced host-based image builds with container-native build tooling that fits pod-based execution.
We evaluated alternative CI platforms, but prioritized a Jenkins-based migration to preserve existing pipelines and reduce transition risk.
Chapter 2 - Implementation
2.1 EKS ecosystem setup
The platform was already running on EKS, so the migration focused on integrating Jenkins cleanly into the existing cluster model. An isolated namespace was used for Jenkins build agents, and IAM permissions were scoped to CI-relevant actions.
2.2 Karpenter setup for Jenkins build workloads
This case study focuses on the Karpenter configuration that supports Jenkins cloud agents.
2.2.1 Capacity strategy
CI capacity is split into a Spot-first pool and an On-Demand fallback pool. NodePool weights prioritize Spot, while CPU limits and instance constraints keep capacity within predictable boundaries. Consolidation and expiration settings reduce idle cost.
2.2.2 Workload isolation model
CI workloads are isolated using label and taint boundaries (workload=ci). Jenkins pod templates opt in with matching nodeSelector and tolerations, which keeps build workloads separated from runtime/application workloads.
2.2.3 Node class baseline
The CI pools use a shared EC2 node class baseline with Amazon Linux 2023, cluster-discovery networking selectors, a dedicated Karpenter node role, and encrypted root volumes sized for build activity.
2.2.4 Architecture-level validation
This case study validates behavior outcomes rather than deployment steps.
Validation focused on four checks: Jenkins pods schedule only on CI-labeled capacity, Spot is used by default, builds continue when fallback On-Demand nodes are required, and CI workloads remain isolated from non-CI workloads.
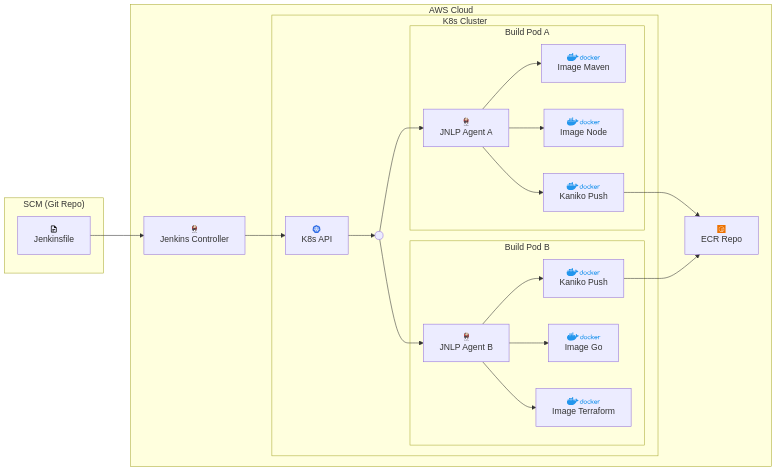
Chapter 3 - Solution architecture
3.1 Solution architectural view (after)

Diagram source: diagrams/jenkins-k8s-pipeline.mmd
3.2 Execution model
The Jenkinsfile defines which pod template and container images are used for each stage. Each build pod includes a JNLP agent container plus one or more task-specific containers. This allows different jobs to use different tool images without changing the Jenkins controller host.
Chapter 4 - Results
4.1 Measurement approach
To keep the comparison fair, the same set of platform-level CI metrics is used in both time periods.
| Metric | Why it is monitored |
|---|---|
| Agent provisioning proxy (p50) | Measures how quickly build capacity becomes available after scheduling. |
| Pipeline queue wait (p95) | Reflects tail-latency queue pressure and developer wait time under load. |
| Infrastructure-related build failures (%) | Separates platform failures from application/test failures. |
| Build non-success rate (%) | Provides an overall reliability signal across selected pipelines. |
| Successful builds (count) | Shows practical throughput across the measurement scope. |
4.2 Results view
- Before period:
2025-12-15 -> 2026-01-12 - After period:
2026-01-19 -> 2026-02-16 - Queue/provisioning metric coverage: 100% in both periods
| KPI | Before | After | Delta |
|---|---|---|---|
| Agent provisioning proxy (p50, sec) | 6.92 | 6.79 | -1.88% |
| Pipeline queue wait (p95, sec) | 9.90 | 9.73 | -1.71% |
| Infrastructure-related build failures (%) | 39.13 | 22.00 | -43.78% |
| Build non-success rate (%) | 43.48 | 26.00 | -40.20% |
| Successful builds (count) | 13 | 37 | +184.62% |
Observed peak concurrent builds in this sample remained 2 -> 2. This is demand-dependent and does not represent the platform’s configured concurrency ceiling.
Build-duration metrics are intentionally excluded from this comparison because workload mix changed after new stages/jobs were added, making direct before/after duration comparisons non-equivalent.
4.3 Notable impact
In practice, the migration shifted build execution from static host limits to elastic capacity and made build environments more consistent through image-based tooling. Teams were also able to add more pre-merge checks (for example linting and static analysis) and run branch validation in parallel without visible queue-pressure regression in the measured periods.
Chapter 5 - Lessons learned
5.1 What worked
Dedicated CI node pools, Spot-first scheduling with On-Demand fallback, and pod-based Jenkins agents provided a good balance of cost control, reliability, and operational clarity.
5.2 What was harder than expected
Normalizing legacy freestyle jobs into pipeline-as-code required more effort than expected, and early observability across queue/provisioning/node behavior was fragmented.
5.3 What we would change in v2
- Define KPI instrumentation and dashboards before migration begins.
- Add policy checks that enforce CI nodeSelector/toleration requirements in Jenkins pod templates.